import pandas as pd
import numpy as np
import scipy.stats as st
import plotly.graph_objs as go
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore', category=FutureWarning)Модули
Превью данных
df = pd.read_csv('2015-street-tree-census-tree-data.csv')
pd.options.display.max_columns = 50
display(df.sample(5))
df.info()| tree_id | block_id | created_at | tree_dbh | stump_diam | curb_loc | status | health | spc_latin | spc_common | steward | guards | sidewalk | user_type | problems | root_stone | root_grate | root_other | trunk_wire | trnk_light | trnk_other | brch_light | brch_shoe | brch_other | address | postcode | zip_city | community board | borocode | borough | cncldist | st_assem | st_senate | nta | nta_name | boro_ct | state | latitude | longitude | x_sp | y_sp | council district | census tract | bin | bbl | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 510728 | 722366 | 317920 | 2016-09-26T00:00:00.000 | 10 | 0 | OnCurb | Alive | Good | Pyrus calleryana | Callery pear | 1or2 | NaN | NoDamage | TreesCount Staff | NaN | No | No | No | No | No | No | No | No | No | 117-027 125 STREET | 11420 | South Ozone Park | 410 | 4 | Queens | 28 | 31 | 10 | QN55 | South Ozone Park | 4084000 | New York | 40.674572 | -73.812771 | 1.036185e+06 | 185096.7568 | 28.0 | 840.0 | 4254706.0 | 4.117470e+09 |
| 61912 | 242195 | 310304 | 2015-09-20T00:00:00.000 | 2 | 0 | OnCurb | Alive | Good | Zelkova serrata | Japanese zelkova | 3or4 | NaN | NoDamage | Volunteer | WiresRope,BranchOther | No | No | No | Yes | No | No | No | No | Yes | 84-081 126 STREET | 11415 | Kew Gardens | 409 | 4 | Queens | 29 | 27 | 14 | QN60 | Kew Gardens | 4013600 | New York | 40.705457 | -73.825723 | 1.032570e+06 | 196341.7012 | 29.0 | 138.0 | 4193207.0 | 4.092480e+09 |
| 233272 | 362349 | 202600 | 2015-10-22T00:00:00.000 | 3 | 0 | OnCurb | Alive | Good | Syringa reticulata | Japanese tree lilac | 1or2 | NaN | Damage | TreesCount Staff | NaN | No | No | No | No | No | No | No | No | No | 17 VAN SICLEN AVENUE | 11207 | Brooklyn | 305 | 3 | Brooklyn | 37 | 54 | 18 | BK83 | Cypress Hills-City Line | 3114600 | New York | 40.679926 | -73.892099 | 1.014178e+06 | 187010.1132 | 37.0 | 1146.0 | 3086843.0 | 3.039180e+09 |
| 15380 | 207687 | 207621 | 2015-09-07T00:00:00.000 | 0 | 34 | OnCurb | Stump | NaN | NaN | NaN | NaN | NaN | NaN | Volunteer | NaN | No | No | No | No | No | No | No | No | No | 2663 CROPSEY AVENUE | 11214 | Brooklyn | 313 | 3 | Brooklyn | 43 | 47 | 22 | BK26 | Gravesend | 3031400 | New York | 40.588756 | -73.990036 | 9.870173e+05 | 153776.2417 | 43.0 | 314.0 | 3187142.0 | 3.069120e+09 |
| 549510 | 16242 | 105877 | 2015-06-10T00:00:00.000 | 21 | 0 | OnCurb | Alive | Good | Platanus x acerifolia | London planetree | NaN | NaN | Damage | Volunteer | Stones,BranchLights | Yes | No | No | No | No | No | Yes | No | No | 1 SUTTON PLACE | 10022 | New York | 106 | 1 | Manhattan | 5 | 73 | 28 | MN19 | Turtle Bay-East Midtown | 1010601 | New York | 40.757302 | -73.960353 | 9.952339e+05 | 215184.5815 | NaN | NaN | NaN | NaN |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 683788 entries, 0 to 683787
Data columns (total 45 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 tree_id 683788 non-null int64
1 block_id 683788 non-null int64
2 created_at 683788 non-null object
3 tree_dbh 683788 non-null int64
4 stump_diam 683788 non-null int64
5 curb_loc 683788 non-null object
6 status 683788 non-null object
7 health 652172 non-null object
8 spc_latin 652169 non-null object
9 spc_common 652169 non-null object
10 steward 164350 non-null object
11 guards 79866 non-null object
12 sidewalk 652172 non-null object
13 user_type 683788 non-null object
14 problems 225844 non-null object
15 root_stone 683788 non-null object
16 root_grate 683788 non-null object
17 root_other 683788 non-null object
18 trunk_wire 683788 non-null object
19 trnk_light 683788 non-null object
20 trnk_other 683788 non-null object
21 brch_light 683788 non-null object
22 brch_shoe 683788 non-null object
23 brch_other 683788 non-null object
24 address 683788 non-null object
25 postcode 683788 non-null int64
26 zip_city 683788 non-null object
27 community board 683788 non-null int64
28 borocode 683788 non-null int64
29 borough 683788 non-null object
30 cncldist 683788 non-null int64
31 st_assem 683788 non-null int64
32 st_senate 683788 non-null int64
33 nta 683788 non-null object
34 nta_name 683788 non-null object
35 boro_ct 683788 non-null int64
36 state 683788 non-null object
37 latitude 683788 non-null float64
38 longitude 683788 non-null float64
39 x_sp 683788 non-null float64
40 y_sp 683788 non-null float64
41 council district 677269 non-null float64
42 census tract 677269 non-null float64
43 bin 674229 non-null float64
44 bbl 674229 non-null float64
dtypes: float64(8), int64(11), object(26)
memory usage: 234.8+ MBДанные можно условно разделить на несколько групп: - идентификаторы; - дата; - численные параметры (диаметры); - категории; - координаты деревьев.
Преобладают категориальные данные.
Пропуски
nans = (df.isnull().sum() / len(df)) * 100
nans = nans[nans > 0]
data = [go.Bar(x=nans.index, y=nans.values, text=nans.values.round(2))]
layout = go.Layout(xaxis=dict(title='Столбцы'), yaxis=dict(title='Процент пропусков'))
fig = go.Figure(data=data, layout=layout)
fig.show()Unable to display output for mime type(s): application/vnd.plotly.v1+jsonПропуски есть лишь в 11 из 45 признаков: - 3 столбца состоят из пропусков на 65+%, пропуски соответствуют категории None из описания; - 8 столбцов с долей пропусков менее 5%.
Исследование признаков
uniques = df.nunique()
data = [go.Bar(x=uniques.index, y=uniques.values, text=uniques.values)]
layout = go.Layout(
xaxis=dict(title='Столбцы'), yaxis=dict(title='Количество уникальных значений')
)
fig = go.Figure(data=data, layout=layout)
fig.update_traces(texttemplate='%{text}', textposition='outside')
fig.show()Unable to display output for mime type(s): application/vnd.plotly.v1+jsonВ основном категориальные признаки имеют 2-3 категории. Больше - у названий деревьев/районов. Признаки с проблемами корней/стволов/ветвей можно попробовать объединить.
corr = df.select_dtypes(include=[float, int]).corr().round(2)
plt.figure(figsize=(12, 6))
sns.heatmap(corr, cmap='RdBu_r', annot=True)
plt.title('Матрица корреляции')
plt.show()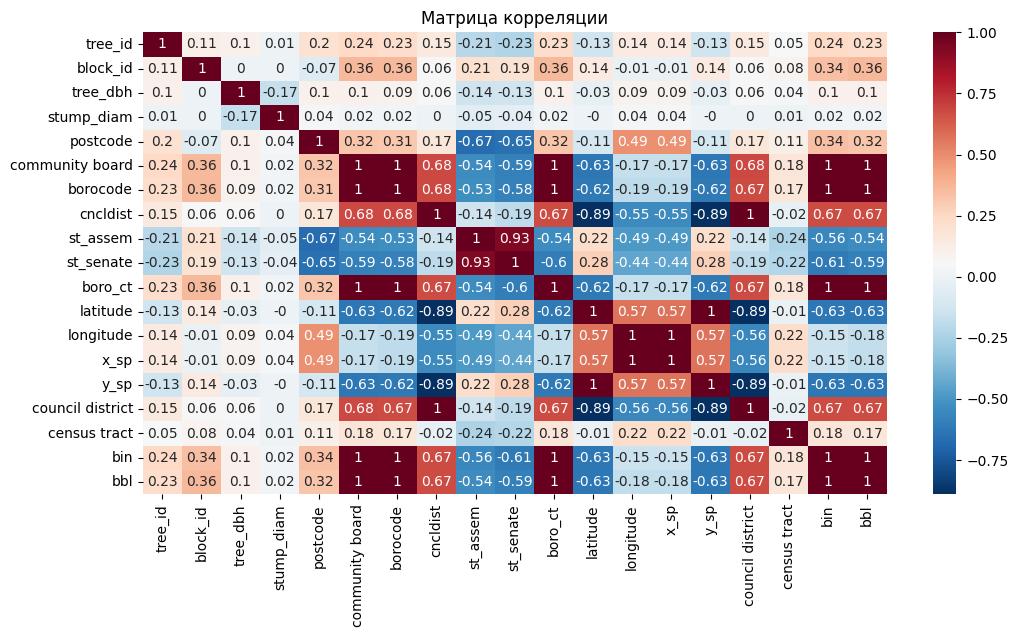
Наблюдается корреляция идентификаторов районов, а также координат. Часть признаков с сильной корреляцией можно исключить из дальнейшего рассмотрения.
sns.pairplot(
df[
[
'tree_dbh',
'stump_diam',
'cncldist',
'st_assem',
'census tract',
'x_sp',
'y_sp',
'bin',
'health',
]
],
kind='scatter',
diag_kind='hist',
hue='health',
).figure.suptitle('Попарное распределение численных признаков', y=1.05)
plt.show()
sns.scatterplot(df, x='cncldist', y='st_assem', hue='borough').legend(
bbox_to_anchor=(1.35, 1)
)
plt.title('Разделение по боро')
plt.show()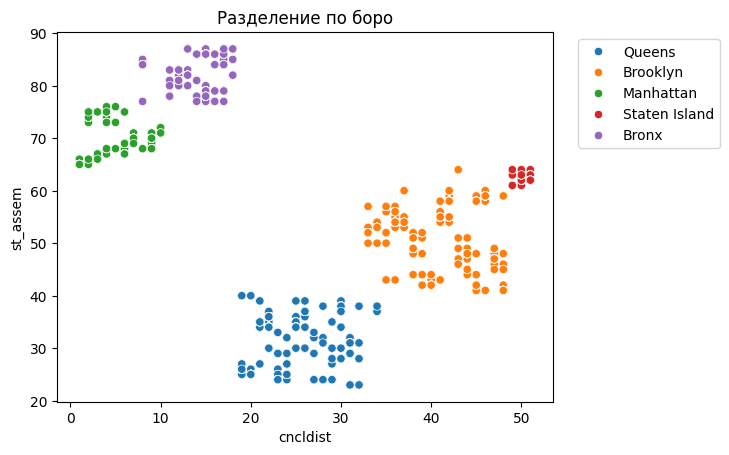
df['health'] = df['health'].fillna('Unknown')
problems = {
'root_problems': ['root_stone', 'root_grate', 'root_other'],
'trnk_problems': ['trunk_wire', 'trnk_light', 'trnk_other'],
'brch_problems': ['brch_light', 'brch_shoe', 'brch_other'],
}
for i in problems:
df[i] = df[problems[i]].apply(
lambda x: 'Yes' if 'Yes' in x.values else 'No', axis=1
)
pairs_health = ['root_problems', 'trnk_problems', 'brch_problems', 'curb_loc']
fig, ax = plt.subplots(2, 2, figsize=(10, 6))
fig.suptitle('Перекрестное сравнение признаков здоровья и проблем', fontsize=16)
for i, pair in enumerate(pairs_health):
pt = pd.pivot_table(
df,
index='health',
columns=pair,
values='tree_id',
aggfunc='count',
margins=True,
)
pt = (pt / pt.loc['All', 'All']).round(2)
sns.heatmap(pt, cmap='RdBu_r', annot=True, ax=ax[i // 2, i % 2])
plt.tight_layout()
plt.show()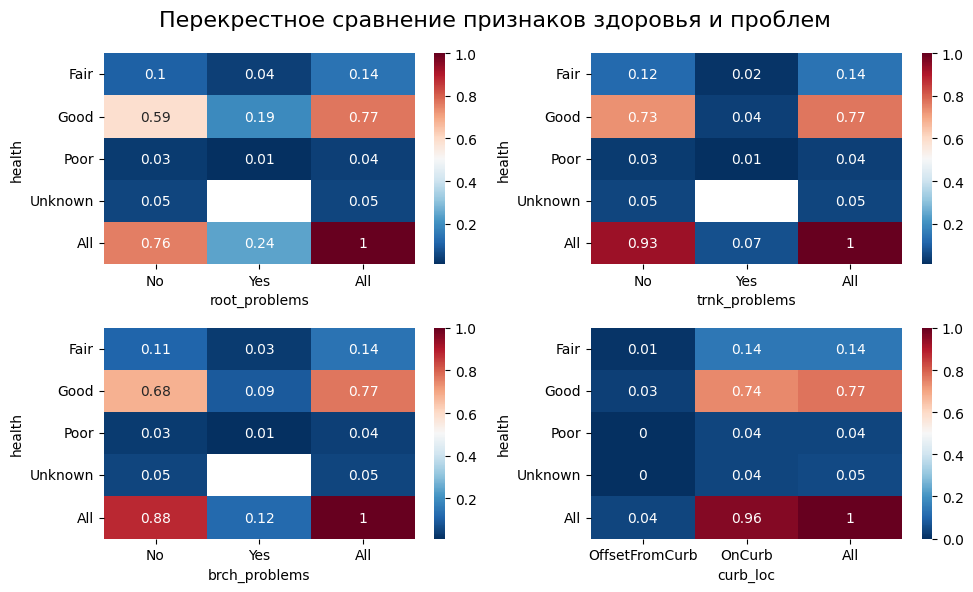
Здоровье деревьев в разных районах может отличаться.
Проблемы с корнями встречаются наиболее часто, но здоровье таких деревьев, как правило, лучше, чем при проблемах со стволами и ветвями.
С помощью признаков cncldist и st_assem возможно однозначно разделить датасет по боро.
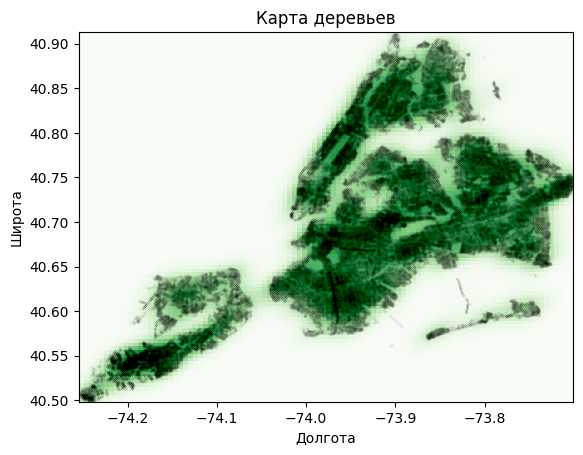
Т.к. в датасете около 700к записей, то из соображений производительности отобразим географическое представление в виде статичного расположения деревьев по широте и долготе без наложения карты местности.
longitudes = df['longitude']
latitudes = df['latitude']
xmin, xmax = longitudes.min(), longitudes.max()
ymin, ymax = latitudes.min(), latitudes.max()
X, Y = np.mgrid[xmin:xmax:100j, ymin:ymax:100j]
kernel = st.gaussian_kde([longitudes, latitudes])
Z = np.reshape(kernel(np.vstack([X.ravel(), Y.ravel()])).T, X.shape)
fig, ax = plt.subplots()
ax.imshow(np.rot90(Z), cmap=plt.cm.Greens, extent=[xmin, xmax, ymin, ymax])
ax.plot(longitudes, latitudes, 'k.', markersize=0.01)
ax.set_xlabel('Долгота')
ax.set_ylabel('Широта')
ax.set_title('Карта деревьев')
plt.show()